

需要予測はなぜ重要か、そして今なぜ問い直されているのか
需要予測は、在庫・生産・調達・物流、すべての計画の起点です。予測が外れれば、欠品による機会損失と過剰在庫のコストが同時に発生します。さらに「ブルウィップ効果」として知られるように、川下の小さな需要変動でも、情報が上流に伝わる過程で増幅され、サプライチェーン全体を揺るがします。小売段階での10%の変動が、メーカーの受注変動では30〜50%にまで膨らむことがあります。需要予測の精度は、個社の問題にとどまらず、サプライチェーン全体の安定に直結しています。
しかし、問題の本質は「精度が足りない」ことではないかもしれません。
かつて不確実性といえば、主に「需要がどれだけ読めるか」という問題でした。だからこそ各社の関心は「いかに精緻に需要予測をするか」に集中し、統計モデルの精度向上が主戦場でした。しかし現在は様相が異なります。需要の不確実性に加えて「供給の不確実性」が急激に高まっています。パンデミック、地政学リスク、気候変動、サイバー攻撃、これらは局所的ではなく、グローバルに同時多発的に起きます。かつての「専門家が時間をかければ解ける問題」から、「因果関係が事前に読めない複雑な問題」へと、サプライチェーンが置かれた状況が変化している。
需要予測で用いられる統計モデルは「過去の延長線上」を予測する道具です。需要の構造が安定していれば機能しますが、コロナ禍のように一夜にして需要パターンが変わると、前提が崩れた瞬間に予測全体が崩壊します。実際に、長年練り上げてきた計画ロジックがコロナ禍では全く機能せず、現場が表計算ソフトと電話で凌ぐ事態となった企業は少なくありませんでした。
「精度を上げれば計画が安定する」という発想そのものを問い直す時期に来ています。求められているのは、精度だけでなく「変化への適応力」です。それが、統計モデルだけでは担えなくなり、MLや生成AIが需要予測の文脈で語られるようになった根本的な理由です。
三つのアプローチの特徴を整理する
需要予測に活用されるAI・分析技術は、大きく三つに分類できます。それぞれの強みと限界を正しく理解することが、使い分けの出発点になります。
統計モデル ―過去の延長線上を予測するー
予測手法:移動平均、指数平滑、ARIMA、SARIMA、Holt-Wintersなど
統計モデルは、過去の時系列データのパターン(トレンド・季節性・周期性)を数式として定式化し、将来を予測します。前提・ロジックが明示されるため、解釈しやすいことが特徴です。
強みは、モデルの挙動が分かりやすく、現場の担当者が結果を理解・説明しやすい点です。機械学習と比較してデータ要件が低く(ただし季節性を含むモデルは2〜3年分のデータが必要)、導入・運用コストも低い点も利点です。安定した環境では高い再現性を発揮します。
一方で弱みもあります。価格・天気・キャンペーンといった外部変数の交互作用など、非線形な関係を捉えにくいことが挙げられます。また構造変化(コロナ禍、市場環境の急変)が起きると前提が崩れ、精度が急落します。
需要予測での役割は「ベースライン生成+人間による修正・合意形成」です。統計モデルが出力するのはあくまでもベースライン、すなわち「過去の延長線上」の予測値です。これを出発点として、需要計画担当者や営業が定性情報(大口顧客の動向、販促計画、競合の動き)を加味して修正し、最終的なコンセンサス予測を形成します。月次のS&OPサイクルにおける需要計画会議がこの合意形成の場となります。統計モデルは「議論の土台」であり、人間の判断なしには計画として完結しません。
ML(機械学習)―多変数の複雑な関係を自動学習するー
予測アルゴリズム:Random Forest、XGBoost、LSTM、グラフニューラルネットワークなど
機械学習は、データから自動的にパターンを学習し、非線形な関係や多変数の交互作用を扱います。2015年頃からSCMへの本格導入が始まり、外部変数(気象・価格・販促)を織り込んだ高精度予測が実現しました。
強みは、気象、競合価格、SNSトレンド、POS実績などの大量の変数を同時に処理できる点です。統計モデルでは捉えきれない複雑な需要パターンを自動学習し、特徴量の重要度が可視化されるため、需要ドライバーの分析にも活用できます。
一方で弱みもあります。大量・高品質なデータが前提のため、新製品・新市場では力を発揮しにくいことがあります。モデルの挙動がブラックボックス化しやすく、現場での説明・納得形成が難しい点も課題です。データサイエンティストなど専門人材が必要で、継続的な再学習・保守の運用負荷も高くなります。さらに、統計モデルと同様に、市場の非連続的な構造変化には弱い面があります。
需要予測での役割は「高精度な定量予測の自動生成+人間は監視・評価・例外対応」です。十分なデータと適切なモデル設計がある場合、機械学習は人間の修正を前提とせずに予測値を直接計画に反映できる水準に達しえます。人間の主な役割は、モデルが想定していない構造変化(新製品投入、競合の大型施策、地政学リスクなど)を検知して例外対応を行うことと、予測精度を継続的に評価してモデルを改善することです。ただし、モデルの出力がブラックボックスになりやすいため、現場の納得感を得にくい点は課題として残ります。
生成AI ―定性情報を読み解き、対話と合意形成を支援するー
代表モデル:LLM(大規模言語モデル:Large Language Model)を基盤とした生成AIツールなど
生成AIは、テキスト・会議メモ・ニュース・営業コメントといった非構造化データを理解し、シナリオ・文章・分析を生成します。SCM6.0の観点では「需要の数値計算そのものより、対話・理解・合意形成を支援する点に強みがある」と位置づけられています。
強みは、過去データがない新市場・新商品に対しても、定性情報をもとにシナリオを生成できる点です。営業コメント・市場レポート・ニュースなど非構造化情報を需要計画に統合でき、S&OP会議の論点整理やリスクシナリオ作成で即効性があります。専門知識が少なくても対話形式で活用でき、計画プロセスの「民主化」を促進します。
一方で弱みもあります。数値計算の精度保証が難しく、確実でない情報を確実かのように生成してしまう「幻覚(Hallucination)」のリスクがあります。単一の数値予測を生成AI単独で行うことは現状不向きです。また企業機密データの入力にはセキュリティリスクへの対処が必要であり、生成結果の正確性を人間が必ず検証する前提となります。
需要予測でのAIに期待される役割は「数値の解釈・対話・シナリオ作成による合意形成の促進」です。生成AIは、統計モデルやMLが出力した数値を「解釈する」場面で力を発揮します。予測値と実績の乖離を自然言語で説明したり、リスクシナリオをS&OP会議向けに文章化したりといった用途が代表的です。数値を「計算する」ツールではなく、計画プロセスの「対話と理解」を支える存在として位置づけると、その適所が見えてきます。
三つのアプローチの比較
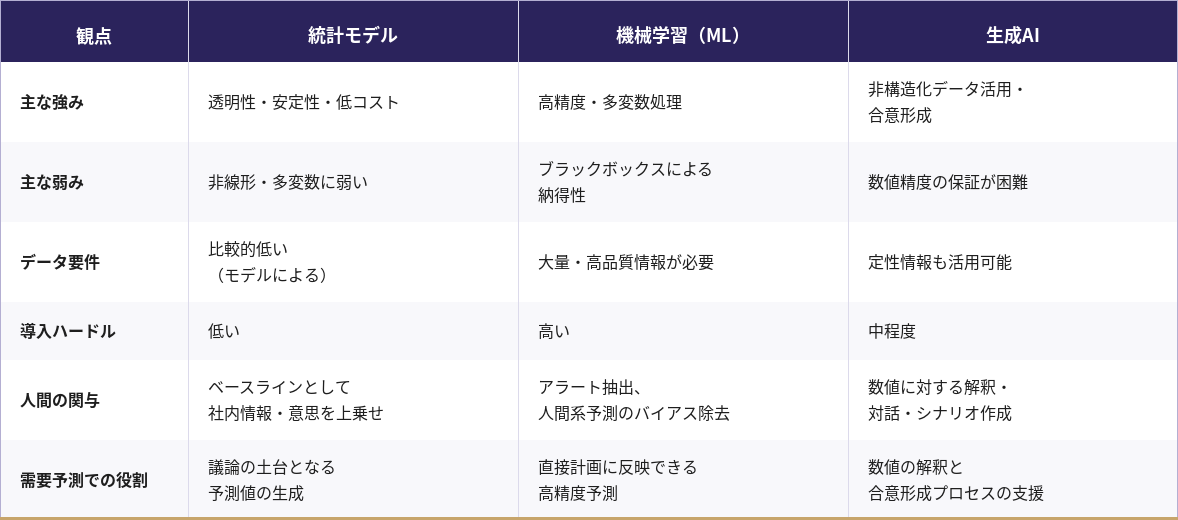
※上記の整理は一般的な傾向を示したものであり、業界・製品特性・データ品質・組織の成熟度によって大きく異なります。自社への適用にあたっては、個別の状況を踏まえた検討が必要です。
どう組み合わせるか ―企業の現在地から考えるー
三つのアプローチは「どれか一つを選ぶ」ものではありません。企業のデータ基盤・組織能力・ツール投資の状況に応じて、組み合わせ方は変わります。以下では、SCMの成熟度別に三つのステージで整理します。
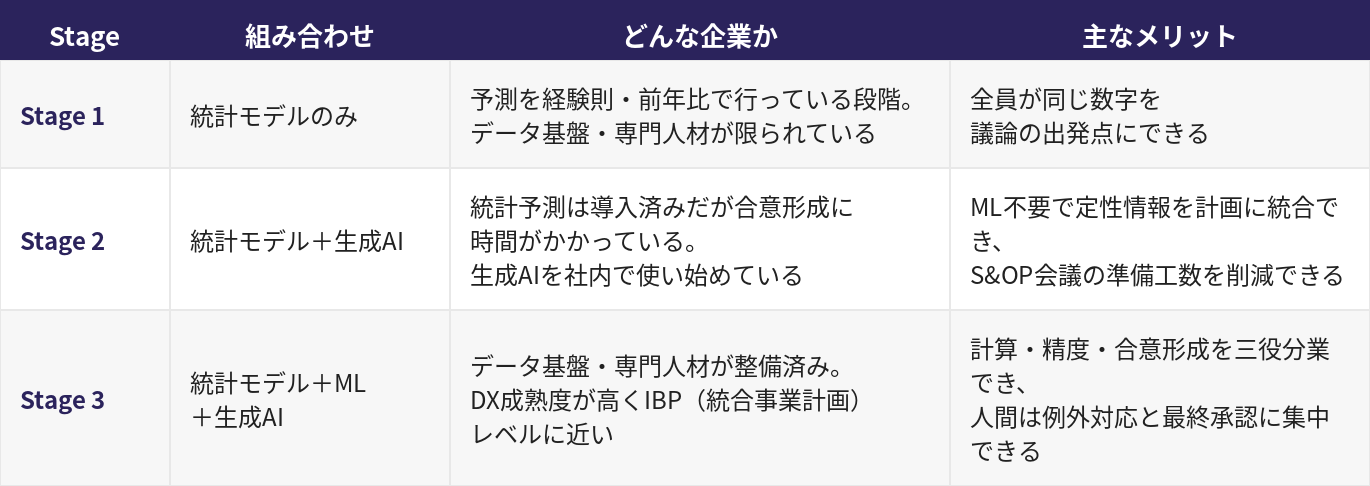
Stage 1|統計モデルのみ ─まず「共通の数字」をつくるー
どのような企業か 需要予測を営業の経験則や前年比で行っており、統計モデルをこれから導入する段階。データ基盤・専門人材ともに限られています。
活用イメージ 月次でARIMAや指数平滑を回し、トレンドと季節性を踏まえたベースラインを生成します。需要計画担当者がそこに営業コメントを加味して手動で修正し、コンセンサス予測とします。
この段階のポイント 精度そのものより「全員が同じ数字を議論の出発点にできる」ことが最大の価値です。まず「共通の土台をつくる」ことが目的であり、ここから始めることが多くの企業にとって現実的な第一歩になります。
Stage 2|統計モデル+生成AI ―合意形成の質とスピードを上げるー
どのような企業か 統計予測は導入済みだが、営業・マーケティングとの合意形成に時間がかかっています。MLはまだ導入していないが、生成AIはすでに社内で使い始めています。
活用イメージ 統計モデルが数値ベースラインを生成し、生成AIが営業担当者のメールや会議メモから「どの顧客が来月増える見込みか」「どのリスクが予測に影響するか」を構造化してS&OP会議の論点として提示します。担当者は生成AIの整理をもとに、どの品目の予測を修正するかを判断します。
この段階のポイント MLがなくても、生成AIによって「定性情報を計画に組み込む精度とスピード」が上がります。S&OP会議の準備工数を削減しながら、議論の質を高められる点が魅力です。現時点でこれが最も多くの企業に実践可能な構成といえます。
Stage 3|統計モデル+ML+生成AI ―計算・精度・合意形成を三役分業するー
どのような企業か データ基盤が整備され、データサイエンティストまたはMLツールを導入済み。S&OPが形式的な数字合わせにとどまらず、事業意思決定の場として機能している企業です。
定常時の活用イメージ 統計モデルがベースラインを生成し、MLが気象・販促・競合価格などの外部変数を組み込んだ高精度予測を自動生成します。生成AIは営業コメントの構造化・会議論点の整理・リスクシナリオの文章化を担い、人間は例外対応と最終承認に集中します。
構造変化が起きた際の活用イメージ コロナ禍のような非連続変化では、MLも統計モデルも精度が急落します。こうした局面では生成AIが「今、何が起きているか」を最初に解釈し、統計モデルの手動修正とMLの再学習へとつなぐ役割を果たします。
この段階のポイント 三つが揃って初めて「計算・精度・合意形成」の三役が分業できます。ただしこの段階に至るには、データ品質・組織能力・ツール投資のすべてが前提条件になります。
三ステージの整理
まとめ ―「どれが正解か」ではなく「今の自社に何が必要か」―
統計モデル・ML・生成AI、いずれも「需要予測を当てるためのツール」として一括りにされがちですが、それぞれが担う役割は明確に異なります。統計モデルは「過去に照らしたベースライン」を、MLは「高精度な予測数値」を、生成AIは「解釈と対話」を担います。
重要なのは、「どれが最も精度が高いか」を競うことではありません。自社のデータ基盤・組織能力・S&OPプロセスの成熟度に照らして「今、何から始めるか」「次に何を加えるか」を判断することです。そして、環境変化に適応しながら、予測という業務にアウトカム価値を生み続ける「弛まぬ」改善プロセスそのものがもっとも肝要と言えます。





