
本連載第3回では、AIとの対話による知識創造メソッド「DIVEモデル」の全体像4ステップと、最初の2つのステップを紹介した。
無知を自覚し、仮説を立てた ―では次に何をすべきか。対話で得た仮説は、検証されて初めて知識になる。そして、その知識は内部化されて初めて、次の「良い問い」を生み出す力になる。前回紹介したステップ1「ソクラテス式AI」とステップ2「AI壁打ち」は、この学習サイクルの入口に過ぎない。最終回となる第4回では、対話で得た仮説を検証し、それを内部化するという後半2つのステップを解説する。
そして改めてDIVEモデルを振り返り、この学習サイクルをどう継続的な成長に変えるかを論じる。「認知的オフローディング」から始まる負のトライアングルから脱却し、知識ベースの拡大から始まる正のトライアングルを回し続ける。これが、AI時代における真の競争優位を手にするための統合フレームワークである。
目次
知識創造のフレームワーク:対話を成長サイクルに変える
「DIVEモデル」のステップ1「ソクラテス式AI」で無知を自覚し、ステップ2「AI壁打ち」でメタ認知の強化を行う。この2つのステップを実践するだけでも、あなたは「消費型」AI活用から「対話型」AI活用へ転換はできる。しかし、AIとの対話によって得られた知見を、検証し、知識として定着させ、それを継続的な成長サイクルに変えなければ、真の競争優位につながらない。AIの出力を消費するのか、それとも活用するのか、この差を生むのは、プロンプトエンジニアリングのようなAIを使いこなす技術ではない。知識を創造し続けるAI活用法であり、学習サイクルの有無なのだ。
2つのステップの振り返り
ステップ1:ソクラテス式AI 無知を自覚する
AIに問いを投げかけさせることで、「自分が何を知らないか」が明確になる。例えば、新規事業検討で「ターゲット顧客の購買力を把握しているか?」と問われ、知識の欠損に気づく。この無知の自覚が、知識ベース拡大のスタートラインだ。
ステップ2:AI壁打ち メタ認知の強化と仮説の導出を行う
特定の領域にフォーカスを絞り、AIと壁打ちを行う。ステップ1で無知を自覚した一つの領域を選択し、さらに問いを繰り返す。この繰り返しの果てに、分からないことがより明確になり、「良い問い」につながる仮説が立ち上がる。
DIVEモデル ステップ3:仮説検証
①仮説検証に近道は無い
ステップ3は、ステップ2の仮説が妥当かどうかを確かめる仮説検証のフェーズである。
ここで断言しておきたいのは、知識ベースの拡大に魔法のような近道はないということだ。顧客との商談、定性・定量調査、現場でしか得られない手触り感のある情報などの一次情報、あるいは文献調査といった二次情報など、これら一つひとつに泥臭く当たり、検証していく。この過程が、現段階では知識ベースを拡大する唯一の方法であり、独自の価値となって、貴社の競争優位性につながるのである。
AIを正しく使えば、その精度やスピードを加速させることは可能だ。例えば、データ分析などはすでにAIが得意だろう。また、Deep Research機能などを使い、出力条件を指定することで、膨大な情報から必要なファクトを揃えることも簡単にできる。しかしながら、それを単に情報として受け取るだけでは、学習効果としてはPassive(受動的)のままであり、「認知的オフローディング」の「消費型」AI活用に過ぎない。データ分析や Deep Research を行う際にも、AIに指示する前に、しっかりとステップ1と2の対話を行い、データ分析の切り口や出力条件を指定する。これが「良い問い」であり、AIを真に使いこなすことになるのである。もちろん、AIを使うのであればその後のファクトチェックの必要性は言うまでもない。
②ゴール:知識ベースの拡大
仮説を検証していく中で、知識が獲得できる。これがステップ3のゴール、知識ベースの拡大だ。例えば、ステップ1で東南アジア市場(インドネシア・タイ)における、ターゲット顧客の消費行動を検討した際に、「映え消費」について分かっていないことが判明した。さらに、ステップ2では、特にその消費を支える「市場規模」や「分野別シェア」の内容が分かっていないことも突き詰めることができた。そこで、「インフルエンサーマーケティング市場は伸びているだろう」「ファッションがトップシェアだろう」という仮説を導く。この検証を一次情報、二次情報で進めていく。すると、その部分についての知識が獲得できるのである。イメージは図1の通り。
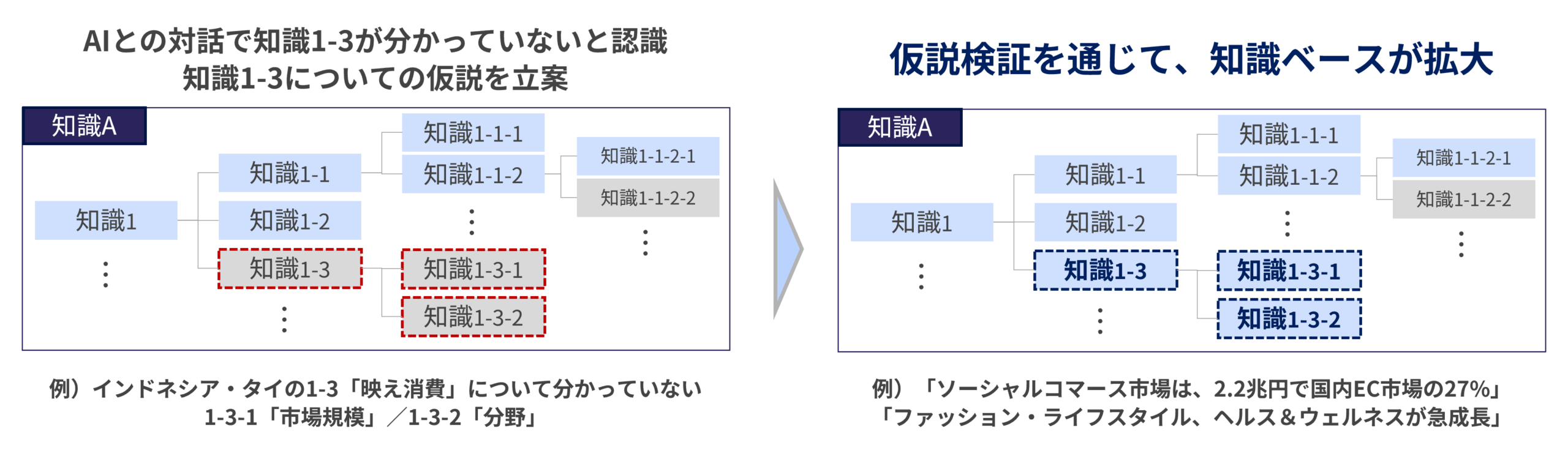
実は、ステップ2で分からないことを明確にして、その上で仮説を導くというステップを踏んでいるのは、第2回で学んだICAPフレームワーク[1]におけるConstructive(構成的)な状態にするためである。単に提示された情報を調べるのと、仮説を立てて調べるという行為では、学習効果が異なる。前者はActive(能動的)、後者はConstructiveな状態となり、後者の方が学習効果は高い。つまり、仮説を立てて検証していくということが、知識ベースの拡大により寄与するのである。
ステップ3の仮説検証で知識ベースの拡大をした後は、最終的にそれを内部化するプロセスに移る。
DIVEモデル ステップ4:内部化
①アウトプットや対話による知識の内部化
仮説検証を通じて知識ベースが拡大した後は、それを自身に内部化するプロセスが重要である。仮説検証の過程では、多様な粒度や視点、種類のインプットが行われる。それを整理しながらアウトプットすることで、改めて知識が構造化され、今後使える知識として記憶が定着する。
興味深い研究がある。エッセイを書くタスクでLLMを使った場合と自身の脳だけで作成した場合を比較したところ、作成したエッセイの内容を記憶しているかどうかに大きな差があり、LLMを使った83%の人は記憶が難しく、残りの人も正確に記憶した人はいなかったという。[2]自身の言葉でアウトプットすることの重要性が非常によく分かる。
この内部化プロセスは、基本的にはプレゼン資料を作る、レポートを書くなどの機会があれば望ましいが、必ずしもそのような機会があるとは限らない。その場合にも、AIを対話相手として使い、AIの質問に対し、自身の得た知識を説明しながら構造化していくことで、内部化が実現できる。具体的な方法は、ステップ2の「AI壁打ち」と同様である。調べた領域を指定し、対話を始める。イメージは図2の通り。
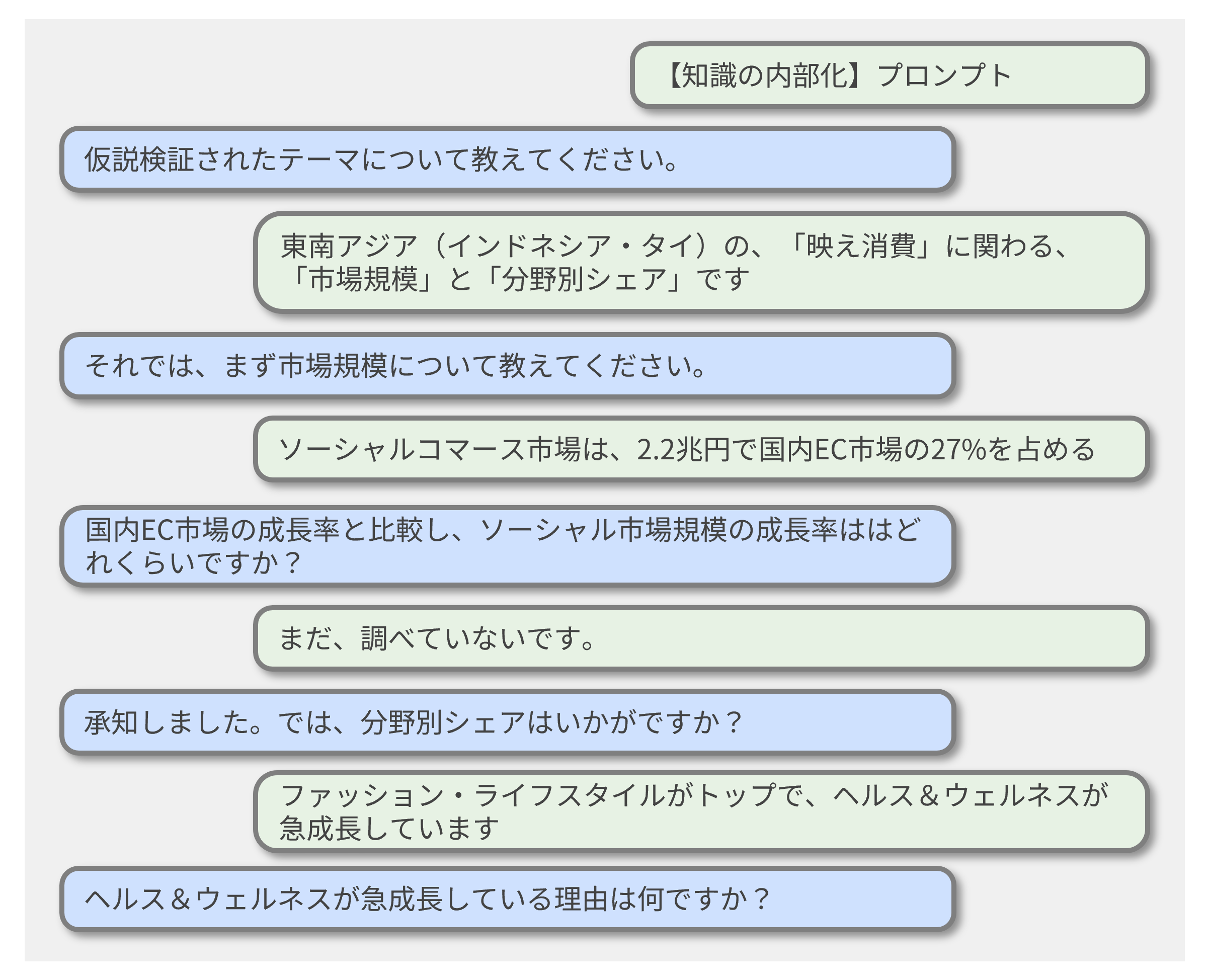
②ゴール:知識の内部化
アウトプットや対話の中で、知識が整理され、定着することがゴールである。AIとの対話を行った場合、おそらく仮説検証する前と後では、質問にクリアに回答できるものも多いはずだ。このステップで最も重要なことは、アウトプットやAIとの対話の中で、個別の知識がつながり合い、新たな関連性が生まれることである。例えば、東南アジア市場(インドネシア・タイ)のソーシャルコマース市場の成長の背景に、欲しいと思ったら即購入を可能にするBNPL(後払い)などの決済システムの存在や、フォロワー数が少ないがエンゲージメントが高い「ナノ・インフルエンサー」の存在といった事柄があることに気づく。この洞察は、AIの出力をそのまま受け取るだけでは生まれない。仮説検証を通じて知識ベースを拡大し、アウトプットや対話で構造化した者だけが手にできるのである。
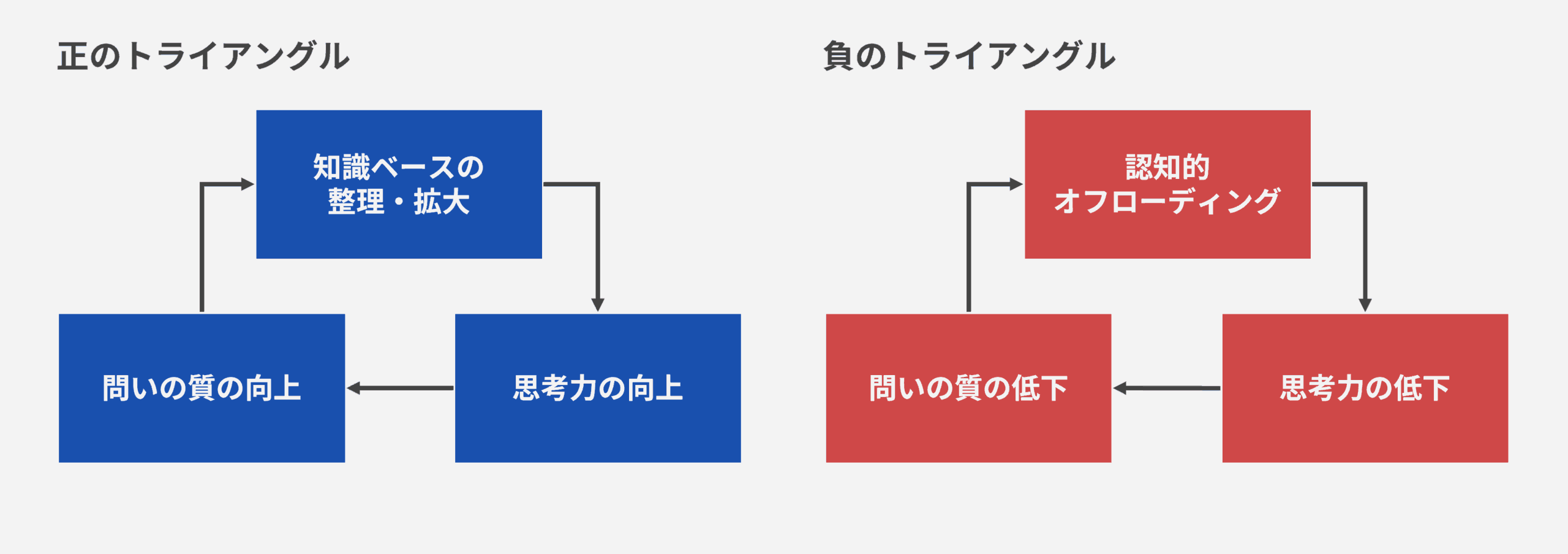
ここまで紹介した4つのステップ、「ソクラテス式AI」「AI壁打ち」「仮説検証」「知識の内部化」は、それぞれが独立したテクニックではない。これらは一連の学習サイクルを形成している。 無知を自覚し(ステップ1)、仮説を導出(ステップ2)、知識ベースを拡大し(ステップ3)、知識を内部化する(ステップ4)。そして、内部化された知識が、さらに次の「良い問い」を生み出し、再びステップ1へと戻る。 この循環が、第1回で見た負のトライアングルを脱却し、正のトライアングル①知識ベースの整理・拡大、②思考力の向上、③良い問いの創出を実現する鍵なのだ。では、この学習サイクルを、どう設計し、回し続けるのか。次に、その統合的な振り返りを行う。
DIVEモデルの振り返り:4つのステップを統合する
第3回で全体像を示したDIVEモデルを、ここで改めて振り返る。4つのステップをご理解いただいた今、その本質をより深く理解できるはずだ。
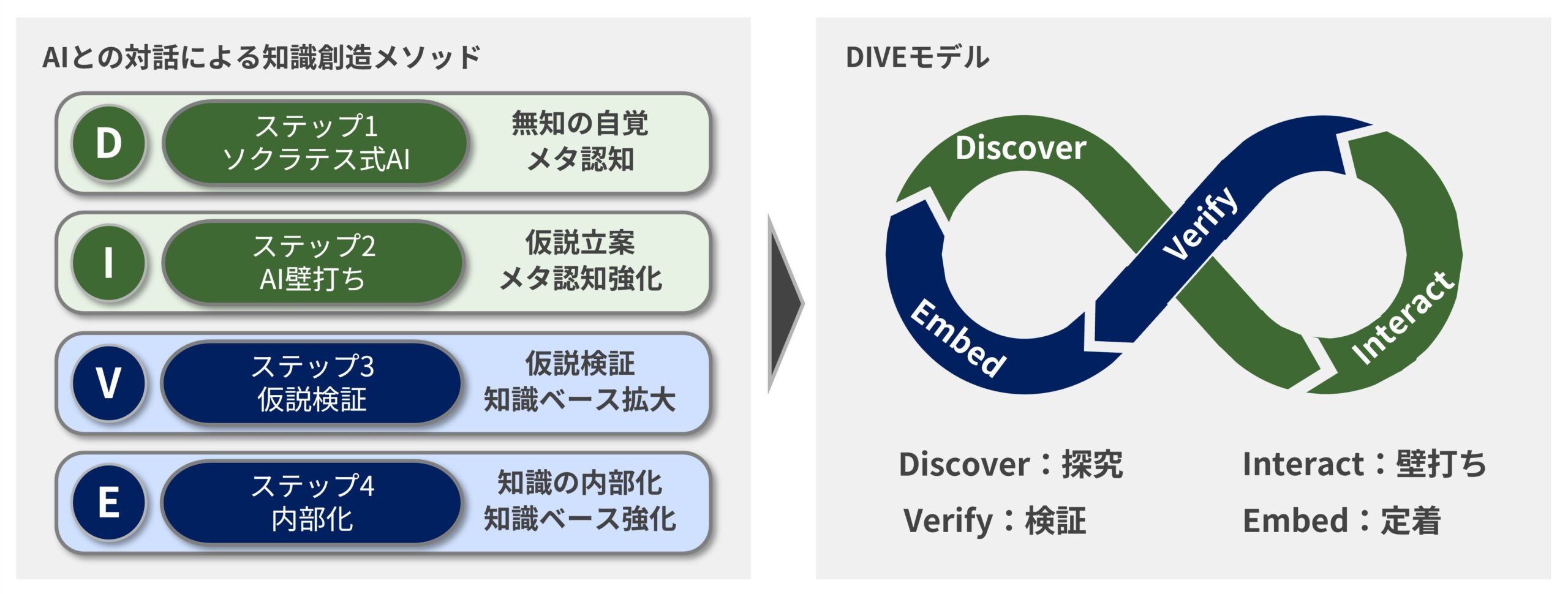
AIとの対話による知識創造メソッド:DIVEモデル
DIVEモデルはここまで説明した通り、以下の4つのステップから構成される。
D:Discover(探究):無知を自覚する
ステップ1「ソクラテス式AI」を使い、自分が何を知らないかを明確にする。Unknown Unknowns(知らないということさえ、分かっていないこと)をKnown Unknowns(知らないと自覚していること)へと変える。これが、知識ベース拡大のスタートラインだ。
I:Interact(壁打ち):仮説の立案
ステップ2「AI壁打ち」を使い、特定の領域にフォーカスを絞る。Known Unknowns に関して、AIと対話を重ね、仮説を立案し、深化させるプロセスである。
V:Verify(検証):知識ベースを拡大する
ステップ3「仮説検証」を行い、一次情報と二次情報を獲得する。仮説を立てて検証するConstructiveな学習が、知識ベースを拡大させる。このステップに近道はない。泥臭いプロセスこそが、独自の価値を生むのである。
E:Embed(定着):知識を内部化する
ステップ4「内部化」で、アウトプットや対話を通じて知識を内部化する。個別の知識がつながり合い、新たな洞察が生まれる。この洞察が、次の深化した仮説、そして「良い問い」を生み出す。
このDIVEモデルの本質は、図3にある通り、終わりなきループにある。知識ベースが拡大すれば、次にAIの出力を受け取ったとき、あなたの「問い」の質は劇的に変化するはずだ。AIの出力を無批判に受け入れるのではなく、自らの知識に照らして、さらに鋭い問いを返すことができる。この好循環が、第1回で提示した正のトライアングル①知識ベースの整理・拡大、②思考力の向上、③良い問いの創出を実現する。一方、AIの出力をただ受け取る「消費型」は、負のトライアングルの①認知的オフローディング、②思考力の低下、③質の低い問いに陥り続ける。
業務への導入:不確実性の高い場面で真価を発揮
DIVEモデルは、すべての業務で使う必要はない。なぜなら、このサイクルは脳に負荷をかけるからだ。したがって、効率性が最優先される定型業務では、このプロセスを省いた方が良い。しかし、第3回のステップ2の中でも言及したが、以下のような不確実性の高い業務においては、真価を発揮する。
- 新規事業の検討
- 戦略立案
- 複雑な意思決定
- それらに付随するリサーチ
これらの場面では、思考の質がアウトプットに直結する。DIVEモデルを省けば、どんなにAIが進化しても、受け取る人間側がその出力の良し悪しを判断できず、腹落ちできない。結果、「AIは使えない」という結論に至る。使えないのは、AIではなく、使いこなせない人間の側なのだ。
ただし、上記に挙げた業務以外でも、ぜひこのDIVEモデルのエッセンスを理解し、意識して業務に取り入れて頂きたい。すべて順を追って行う必要はない。しかし、AIと「対話」するというマインドセット、これだけでも転換できれば、AIは「検索エンジンの進化版」から「思考のパートナー」へと変わるのである。
おわりに
本連載は、筆者のコンサルティング実務における問題意識が発端である。AIを使う人の経験や知見の差が、その活用方法に差を生み、それが埋めがたい格差を広げている。この現実に、筆者は強い危機感を抱いた。AIの出力をただ消費するのか、それとも活用して自身の知識として蓄積するのか。その差は、想像以上のスピードで広がるだろう。AIは組織全体の能力を底上げするどころか、格差の増幅器として機能しているのだ。
しかし、見方を変えれば、チャンスでもある。なぜなら、基礎知識や思考体力は、後天的に獲得できるものだからだ。しかも、我々は24時間365日、嫌な顔一つせずに応えてくれるディスカッションパートナーを手にしている。AIとの対話を、今すぐ始めることができる。
本連載で紹介してきたDIVEモデルを回し続けることで、AI活用は「消費型」から「対話型」へと転換され、AIをレバレッジできるようになる。これこそが、AI時代における真の競争優位の源泉となる。
本稿が、AIを導入したが期待した効果が出ていないとお悩みの方、新規事業や戦略立案がなかなかうまく進まない方、その他AI活用に悩むすべてのビジネスパーソンにとって、AIの効果的な活用を実現する一助となれば幸いである。
参考文献
[1]Taylor & Francis(2014), “The ICAP Framework: Linking Cognitive Engagement to Active Learning Outcomes”, https://www.tandfonline.com/doi/abs/10.1080/00461520.2014.965823(参照2026年2月9日)
[2]arXiv(2025), “Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task”, https://arxiv.org/abs/2506.08872(参照2026年2月9日)








