
本連載の第1回では「売り場づくりの考え方を再定義する必要性」について説明し、第2回では「筆者の提案するデータドリブンアプローチの有用性」についてロイヤルカスタマー戦略を例に解説した。
ここまでご覧いただいた読者の皆さまに残る疑問は恐らくあと1つだろう。「本当にそんなことが実現できるのか?理想に理想を重ねた机上の空論ではないか?」
そういった疑問に応えるべく、筆者は第2回で紹介した変分オートエンコーダー(VAE)のPythonプログラムを独自に作成し実際にID-POSデータ(顧客IDがひもづいたPOSデータ)を分析することで、本当にビジネス上有益なアウトプットが得られるか検証を行った。
第3回ではVAEの具体的な仕組み、および筆者が行った検証内容・結果を具体的に解説していく。VAEを正確に理解するには数理統計学、プログラミングなどの理解が必要だが、本稿ではそういった専門知識を可能な限り排し直感的な理解を促すよう努めた。それでもやや難易度の高い部分を含むが、価値あるレポートに仕上がったと確信しているため是非ご一読願いたい。
はじめに
本稿の執筆にあたり、2点あらかじめ断っておきたい。
1点目はやや専門的な内容を含むことだ。全体を通して数学、プログラミングなどの知識を必要としない内容だが、第3章では検証結果を詳細に紹介しているためグラフやプロット図を読む必要がある。あらかじめご了承いただきたい。
2点目は厳密さより分かりやすさを意識している点だ。学問的厳密性と直感的な分かりやすさの両立を心掛け執筆したが、トレードオフを避けられない部分では後者を優先している。統計学や数学、機械学習に造詣の深い読者の皆さまにとっては気になる点も多い内容だと想定するが、こちらについてもご理解いただけると幸甚である。
第1章:VAEとは何か
<圧縮と復元――ZIPファイルとの比較から>
VAEを理解するための手がかりとして、まずZIPを思い浮かべてほしい。ZIPとはファイルデータを圧縮して容量を小さくし、必要なときに元の状態ファイルへ復元する技術だ。多くの人がZIPファイルを使ってのデータ送受信をしたことがあるだろう。VAEが行っていることも、この「圧縮して復元する」という考え方に近い。つまりVAEとは情報を圧縮し、それを復元する装置のようなものである。
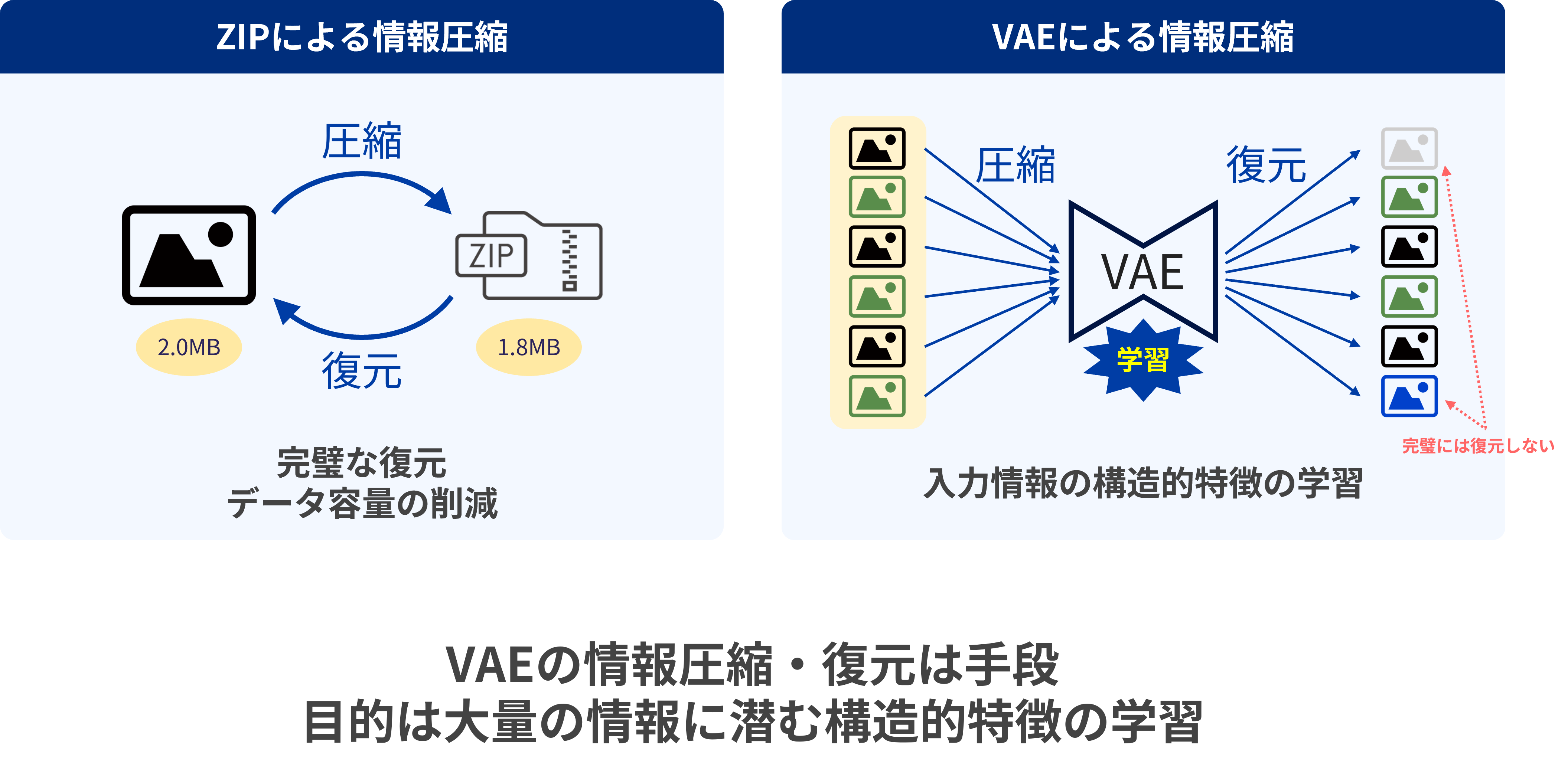
これが何の役に立つのか。その答えは、VAEによって巨大なデータに潜む本質的な特徴を自律的に捉えられることにある。ZIPとVAEのどちらも情報を圧縮・復元するが、決定的な違いとしてその目的が異なる。ZIPは対象とする情報の全てを欠損なく完璧に復元することを目指す。そのためZIPによる圧縮・復元において対象ファイルは1つずつ個別に処理される。ここに複数のファイルの共通構造を捉えよう、などといった意図は存在しない。
対してVAEの目的は、圧縮・復元を通じて入力された情報の構造的特徴を「学習」することだ。このとき、VAEは膨大なデータを何度も繰り返し処理することで、データ間に共通する構造を少しずつ学習していく。例えば画像データをVAEで学習する場合、数千枚~数百万枚の画像を繰り返し処理する。そのため画像と画像の間にある主要な特徴を捉えることができるようになるのだ。ただし、その過程でVAEは圧縮した情報を完璧には復元しない。細部まで完璧に再現しようとすれば、データの枝葉末節にとらわれて本質を見失うからだ。あえて細部を捨て、復元に本当に必要な情報だけを残すことで、VAEはデータの本質的な構造を学習できるようになる。
<学習と圧縮が作り出す潜在変数とは>
VAEは入力された膨大な情報を横断的に捉え、どの情報を残し、どの情報を捨てるか繰り返し判断する。この学習プロセスの結果として、元の膨大な情報は少数の情報に圧縮される。この圧縮された情報を「潜在変数」という。本セクションではこの潜在変数の正体を明らかにしていく。
想像していただきたい。読者の皆さまが友人と「絵しりとり」をしているとしよう。ご友人が「ドア」の絵を提示し、続くあなたは「アザラシ」をひらめいたとする。この時、あなたはどのように気を付けて絵を描くだろうか。きっとアザラシの特徴を表現しようと努めるはずだが、気を付けなければアシカなどよく似た動物と間違われる可能性がある。したがって「耳たぶは描かない」「前脚は短く描く」「ゴマ模様を描く」など、アシカにはないアザラシの特徴を確実にとらえることが肝要だろう。
ここでアザラシの毛並みや爪の形などをリアルに表現しても仕方ない。アザラシという動物を的確に表現するには、アザラシの本質を突いた特徴が必要なのだ。VAEは学習を繰り返しながらこのような本質的特徴を潜在変数に集約する。つまり潜在変数とは元データを特徴づける重要な特徴情報の塊と理解してよいだろう。
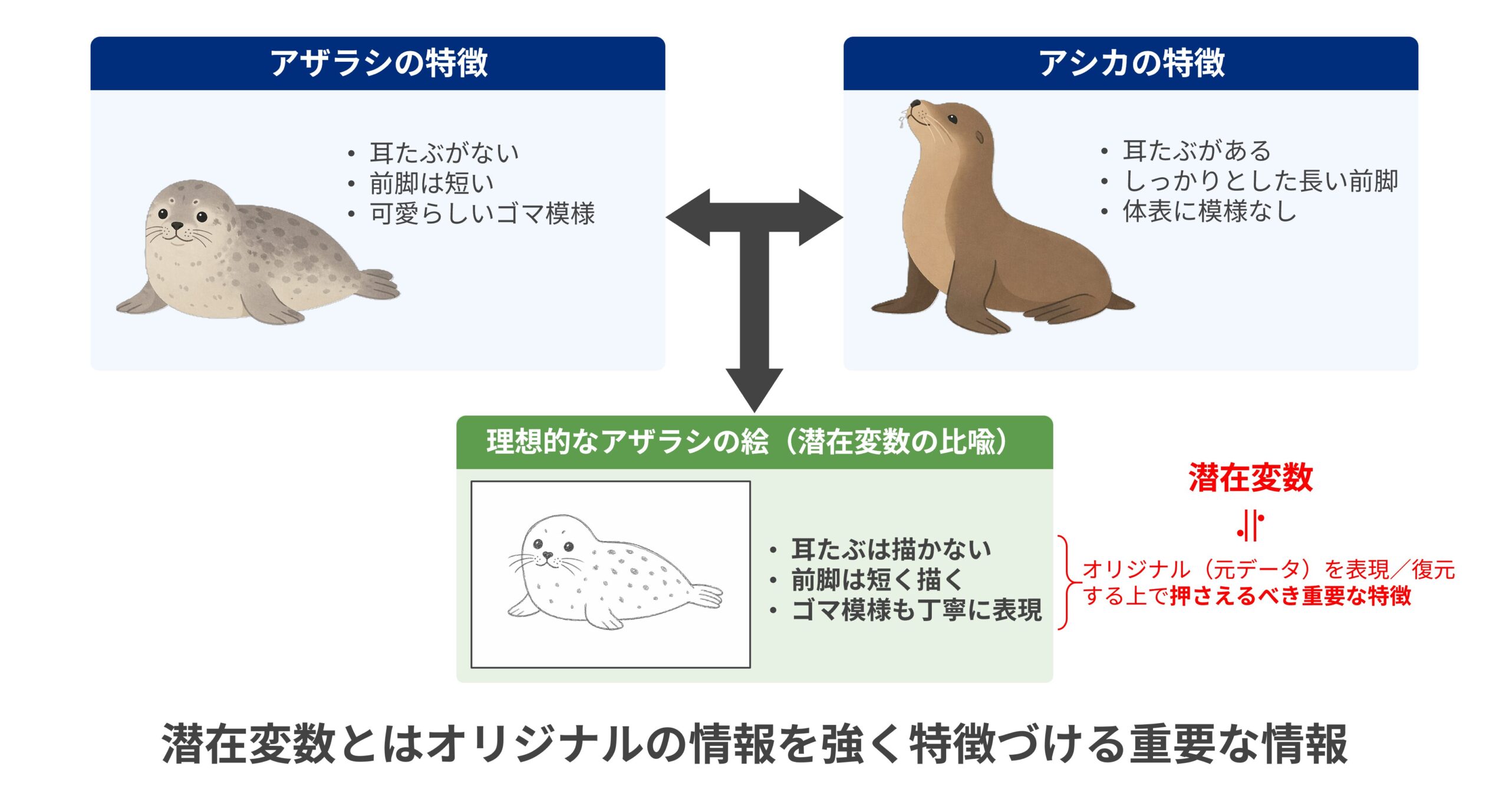
ここまで絵しりとりの例を用いて潜在変数を説明してきたが、実際にVAEにアザラシの画像を大量に投入しても潜在変数にはアザラシをアザラシたらしめる重要な特徴が刻まれるだろう。つまり「耳たぶの有無」「前脚の長さ」「ゴマ模様の有無」といったアザラシを的確に表現にするための重要な特徴だけが自然と潜在変数に残るように学習が進む。特筆すべきは、こうした特徴を人間があらかじめ指定する必要がない点だ。VAEはあくまでデータの構造から、再現に必要な情報を自律的に学習し潜在変数を形成するのだ。
第2章:VAEによるID-POSデータ分析
<分析の背景>
「VAEにID-POSデータを投入すると、いったいどのような分析結果が得られるだろうか。」
筆者はこの疑問の先に小売りビジネスの変革の可能性を感じ取った。本連載の第1回、第2回で述べたように、小売業の売り場とは「多数の顧客が多数の商品と出会う場」であり、これを人間の認知機能で最適化することは不可能である。そこで重要となるのは多数の顧客に共通する需要構造を俯瞰的に捉え、それを売り場づくりに反映させることだ。
ここで筆者は1つの仮説を立てた。
「どんな商品を購買したかという購買実績データの裏には、その人の嗜好性やニーズという本質的な特徴が隠れているのではないか。であれば、VAEに購買実績データを大量に投入することで、圧縮された情報として顧客の嗜好性やニーズを取り出せるのではないか。」
筆者はこの仮説を検証すべく、以下の通り分析を設計した。なお一般的にVAEの構造やさまざまな設定事項は全てPython等のプログラミング言語で記述される。一般的なBIツールでの実践は難しいが、裏を返せば貴社のシステムエンジニアやデータサイエンティストがほぼノーコストで実装することも十分に可能だろう。
<使用したデータセット>
まずはVAEに投入するID-POSデータの説明である。今回の分析に使用したのは、米国の食料品デリバリーサービスであるInstacartが公開しているID-POSデータだ。誰でもKaggle(カグル)から無償ダウンロードできるオープンデータであり、3,421,083件の購買レコード、206,209人のユーザー、134種類の商品小分類など複数のデータテーブルが収録されている。[1]
このデータを選んだ理由は2つある。1つは規模と構造が実際の小売企業のID-POSデータに近く、分析の汎用性を検証するうえで適切な素材であること。もう1つはこのデータセットは非常に少ない情報量しか持たないシンプルなデータセットであることだ。
後者についてもう少し言及すると、このデータセットから分かることは「どの会員IDが、どの商品小分類の商品を、何個買ったか」という極めてシンプルな事実だけだ(*1)。年齢・性別・住所などの個人属性や商品の定価、プロモーション有無などの情報はデータセットに存在しない。
実のところ、ID-POSデータを保有していても顧客属性とのひもづけが不十分、あるいは価格や販促の情報が整備されていない小売企業は少なくない。だからこそ必要最低限のデータからビジネスインパクトにつながる示唆を得ようとする今回の試みには少なからず意義がある。
(*1)厳密には個人の平均購買頻度(日数)などの情報も含むが今回の分析では使用していない。
<入力データの設計>
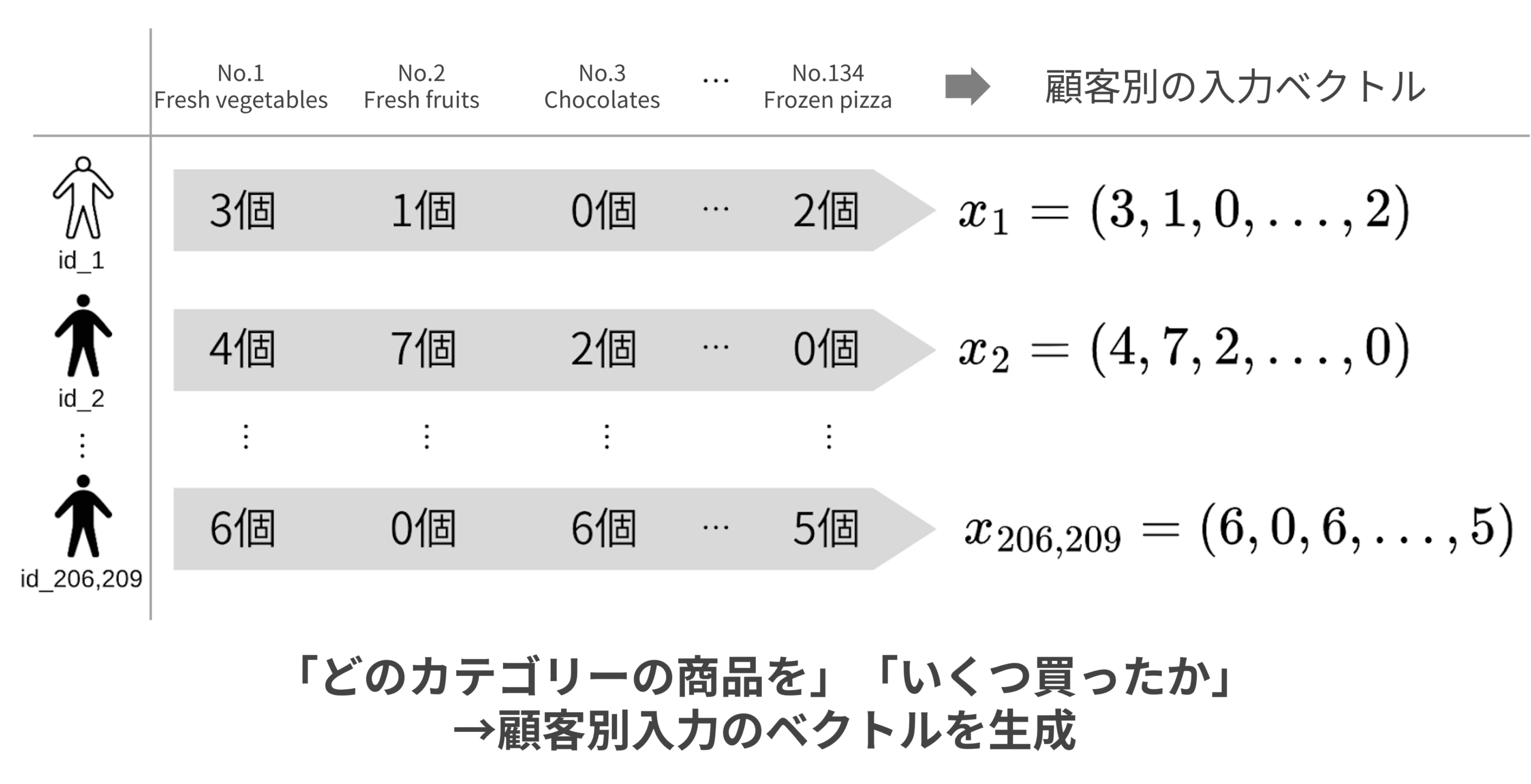
次にID-POSデータをVAEに投入できる形に整形していく。通常VAEには複数のベクトルデータが投入される。やや難解に聞こえるが、図3を見ていただければそこまで複雑ではないと感じていただけるはずだ。
図3の左側では「どの商品カテゴリーの商品を、いくつずつ購買したか」という情報を顧客別に整理している。例えば[id_1]という顧客は、生鮮野菜(No.1 Fresh vegetables)を3つ、生鮮果実(No.2 Fresh fruits)を1つ買ったことが分かる。Instacart datasetにおいて商品カテゴリーは134種類あるため、カテゴリーごとの購買数を横に並べていくと、図3右側のようにx1=(3,1,0,…,2)という134個の数字の並びができあがる。これが[id_1]という顧客の“顧客ベクトル”だ。この顧客ベクトルは1人の顧客につき1つ作られるため、これを206,209人分用意すれば、VAEに投入する入力データの完成だ(*2)。
以降の説明に備え、「次元」という言葉についても簡単に説明しておく。先ほど作成した顧客ベクトルにはそれぞれ134個の数字が収まっている。この数字の個数を「次元」と呼ぶ。つまり顧客ベクトルは全て134次元データである、と表現されることになる。これを踏まえて次へ進んでいただきたい。
(*2)厳密にはデータスケールの補正など正常な学習に必要な特徴量操作を加えている。
<VAEの詳細・検証モデルの設計>
ここではVAEの構造について説明する。やや抽象的な内容が増えるが図4を頼りにイメージだけでも掴んでいただければ十分だ。
先述の通りVAEを“情報を圧縮・復元する装置”と表現するなら、圧縮用の機能はエンコーダー、復元用の機能はデコーダーと呼ばれる。そしてエンコーダーとデコーダーの間で作られるのが圧縮された情報、潜在変数である。つまりVAEに投入されるデータはまずエンコーダーを通って潜在変数に変換され、この潜在変数がデコーダーを通ると復元データに変換されるのだ。
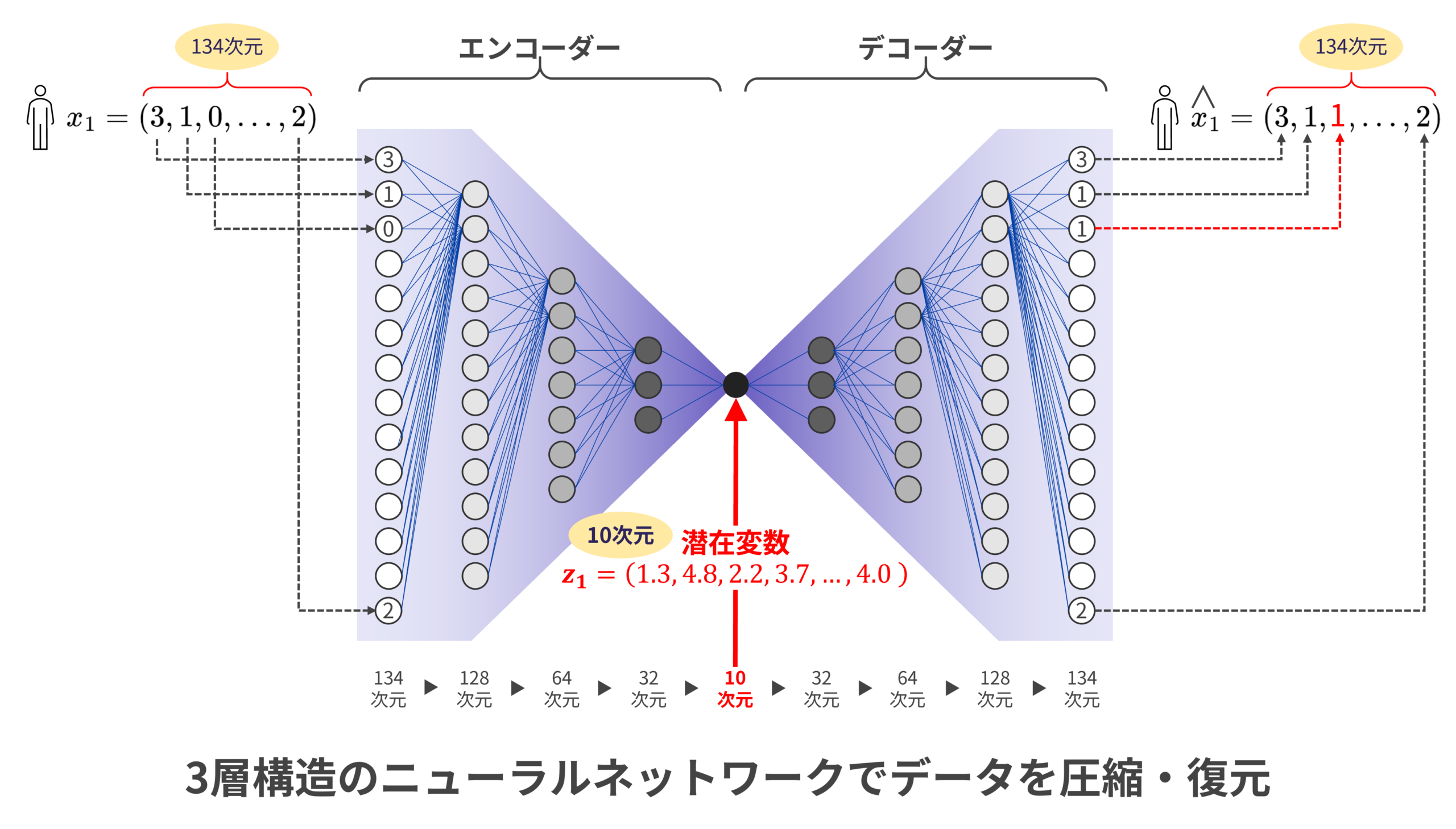
この流れをもう少し詳しく見てみよう。図4は[id_1]という顧客の顧客ベクトルをVAEに投入した時のイメージ図である。簡潔に言えば、エンコーダーが行う情報の圧縮とは“入力ベクトルの次元の削減”である。先に述べたように顧客ベクトルx1は134次元である。これをエンコーダーに通すと複雑な計算を経て最終的に10次元の情報、潜在変数が作られる。つまり潜在変数は10次元のベクトルz1なのだ。
これは重要なことを意味する。134次元の顧客ベクトルは、「[id_1]という顧客を134種類の情報で表現したもの」と解釈できる。まさに「この人は、野菜を3個、果実を1個、チョコレートを0個、…冷凍ピザを2個、買う人である。」といった理解でよいだろう。すると潜在変数はどう見えるだろうか。10次元ベクトルである潜在変数z1は「[id_1]という顧客をたった10種類の情報で表現したもの」と解釈できる。このメリットは大きい。なぜならより少数の重要な情報で顧客を表現する方が人間にとってはるかに理解しやすいからだ。
以上を踏まえると今回の検証で用いたVAEの構造も理解できるはずだ。入力データは134次元であり、これをエンコーダーで128次元、64次元、32次元と段階的に圧縮し、最終的に10次元の潜在変数を生成する。この逆の流れで、デコーダーは10次元から32次元、64次元、128次元、134次元へと復元する。
この構造は筆者が試行錯誤した結果であり、全てのケースでVAEがこの構造になるわけではない。同様に潜在変数の次元数を10次元としたことも筆者による設定である。この次元数は分析者が任意に設定するものだが多すぎても少なすぎても分析・解釈が難しくなる。今回は試行錯誤を経て10次元を採用した。特徴量設計や損失関数の定義、正則化項のパラメーター調整などさまざまな試行錯誤を経てモデリングを行ったが、これらの詳細は本稿の主旨から逸れるため割愛する。
第3章:分析結果と考察
ではいよいよVAEによる分析結果を見ていく。
本章ではVAEプログラムの実行によって出力されたグラフやプロット図を確認しながら、その意味を順に解釈していく。
先述の通り、VAEが生成した10次元の潜在変数は、“10種類の情報で各顧客を説明していると解釈できる”。しかし10種類の情報のどれが重要で、何を意味するのか、を直接知ることはできない。ここで必要なのが分析結果の解釈である。そこで本章では分析結果を3つのステップに分けて解釈していく。ステップ1では潜在変数が持つ10次元情報のうちどれが重要か見極めていく。ステップ2では重要そうな次元が何を意味するのか具体的に解釈していく。最後のステップ3では顧客全員を俯瞰した時VAEによって発見した傾向がどのように存在しているか観察していく。
<ステップ1:意味のある潜在変数はどれか?>
まずは潜在変数が持つ10種類の情報のうち、重要度の高いものを見つけよう。ここで使うのがKLダイバージェンス(*3)という指標である。詳細は割愛するが、この値が大きいほどその次元により多くの情報が凝縮されている、と解釈いただきたい。
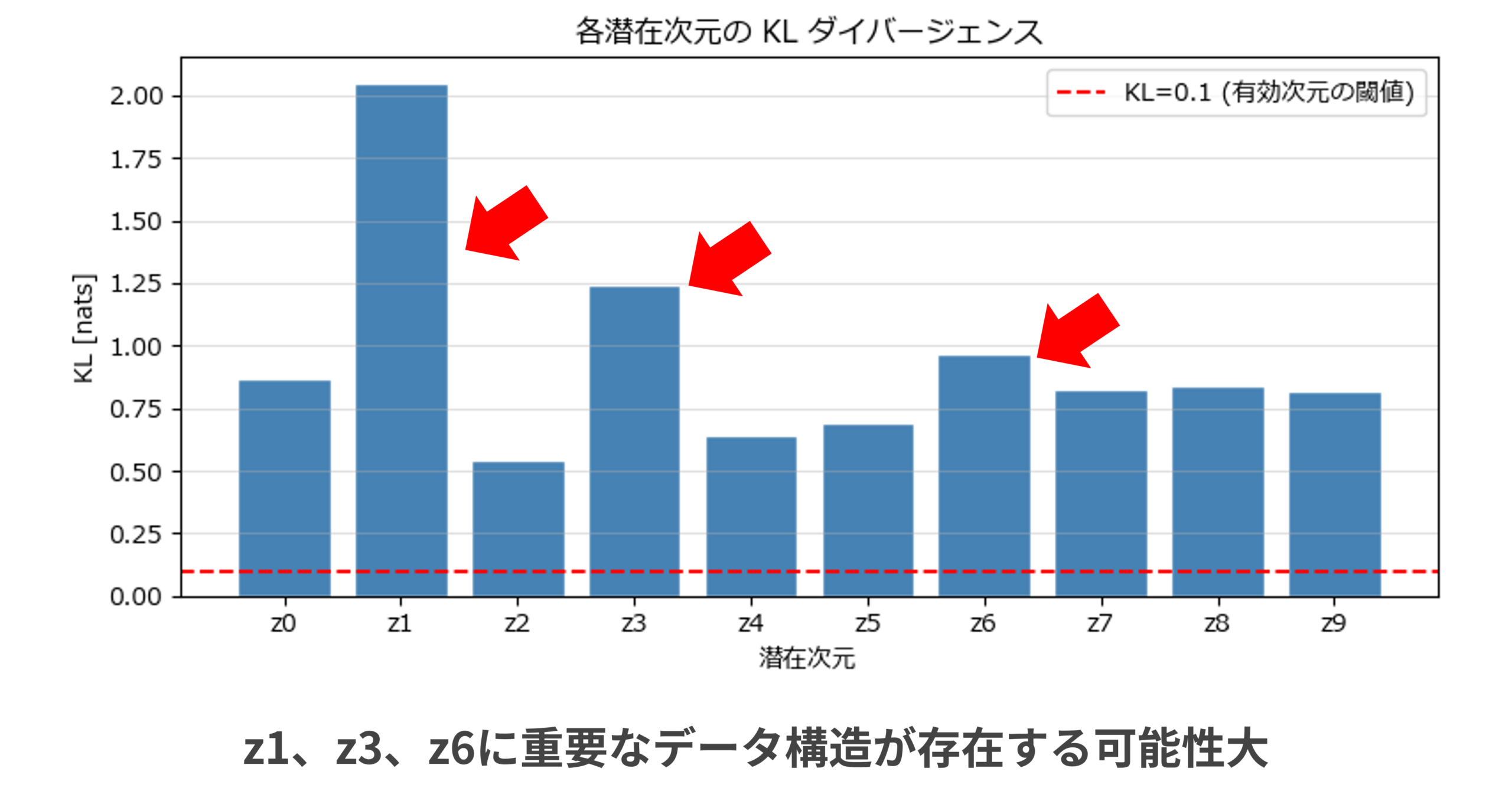
図5を見ると、10次元すべてにおいてKL値が閾値(0.1)を大きく上回っており、学習を通じて各次元が情報の復元において重要な情報を持っていることがわかる。中でもz1、z3、z6の3軸は特にKL値が高く、顧客の購買行動を説明する上で本質的な情報を保有していると考えられる。したがって以降はこの3軸にフォーカスして解釈を進める。
(*3)VAEにおいて潜在変数の10次元はそれぞれ「標準正規分布に近い振る舞いをすること」と「元データをできるだけ正確に復元すること」の2つを同時に満たそうとする。しかし両者はトレードオフの関係にあり、データを正確に復元するためには標準正規分布からの逸脱が必要となる。この逸脱の程度を定量化したものがKLダイバージェンスである。KL値が大きいということは、その次元が標準的な振る舞いから大きく外れており、結果としてデータの復元に必要な情報を多く担っている可能性を示唆する
<ステップ2:潜在変数は何を表しているのか?>
次にz1、z3、z6の3軸が具体的に何を表す数字なのか考察していこう。10次元の潜在変数は、そのままではただの10個の数字の羅列でしかない。しかし興味深いことに、この中の特定の数字を少しだけ大きくしたり小さくしたりすると、それに反応してデコーダー側で復元される134次元のベクトルでも値の増減が観測できる。
ここで思い出していただきたい。デコーダーから出てくる134次元のデータは、134種類のカテゴリーごとの購買数量を表す。ということは潜在変数を変化させることで、これに影響されて購買数量が増加するカテゴリー、変わらないカテゴリー、減少するカテゴリーを見分けることができるのだ。このようにして潜在変数の各次元と元データの各次元(ここでいう商品カテゴリー)の関係を調べる手法をトラバーサル分析と呼ぶ。
では実際に、z1、z3、z6の順にその値を-3から+3に動かした場合のトラバーサル分析を見ていこう。
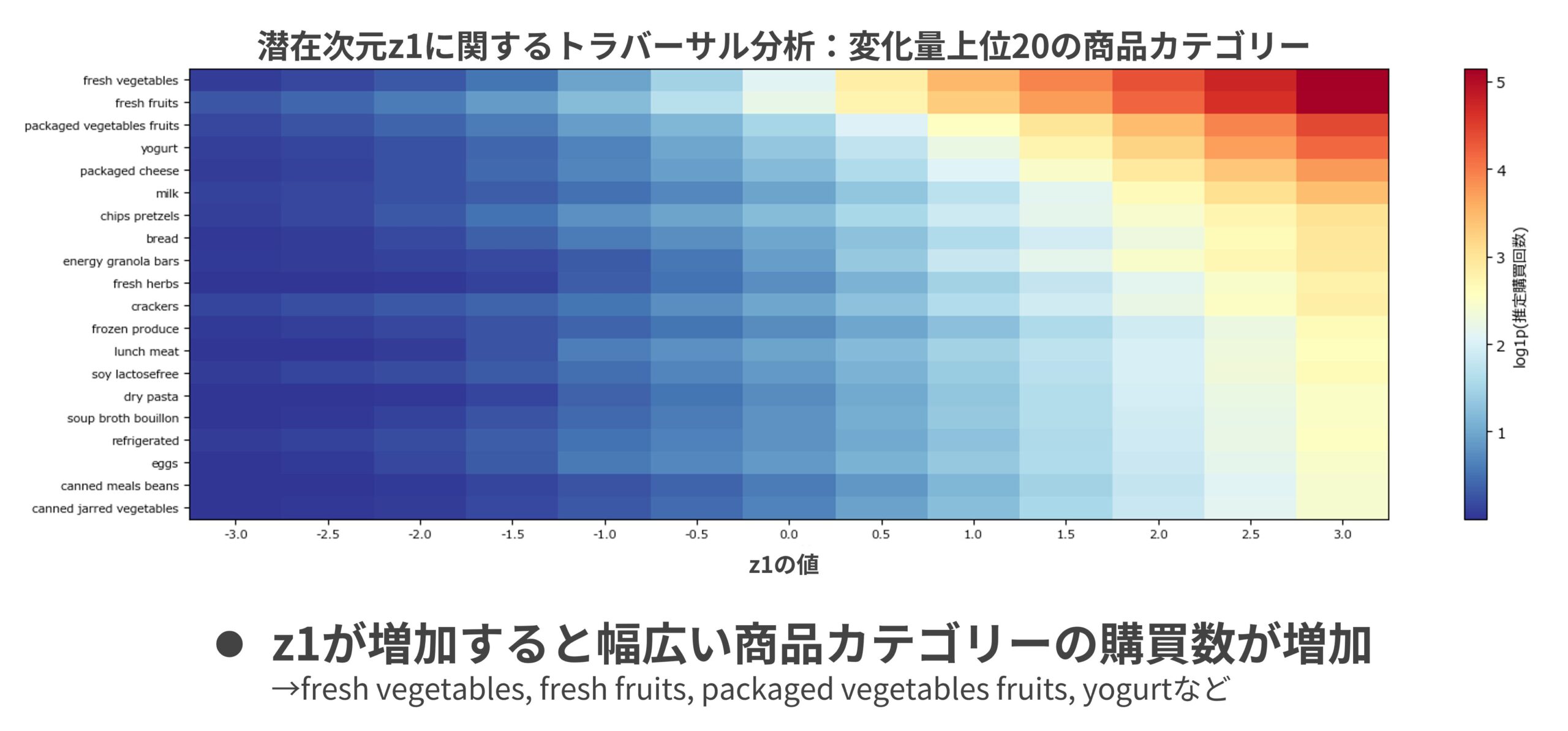
z1軸:購買アクティブ度
図6はz1軸に関するトラバーサル分析の結果だ。z1の値を増加させると、分析対象となったほぼすべての商品小分類で購買数の予測値が一様に増加した。特定のカテゴリーへの偏りはなく、購買全体の量と幅が拡大する。この軸は顧客の購買アクティブ度、すなわち「どれだけ積極的に買い物をするか」を表現していると解釈できる。
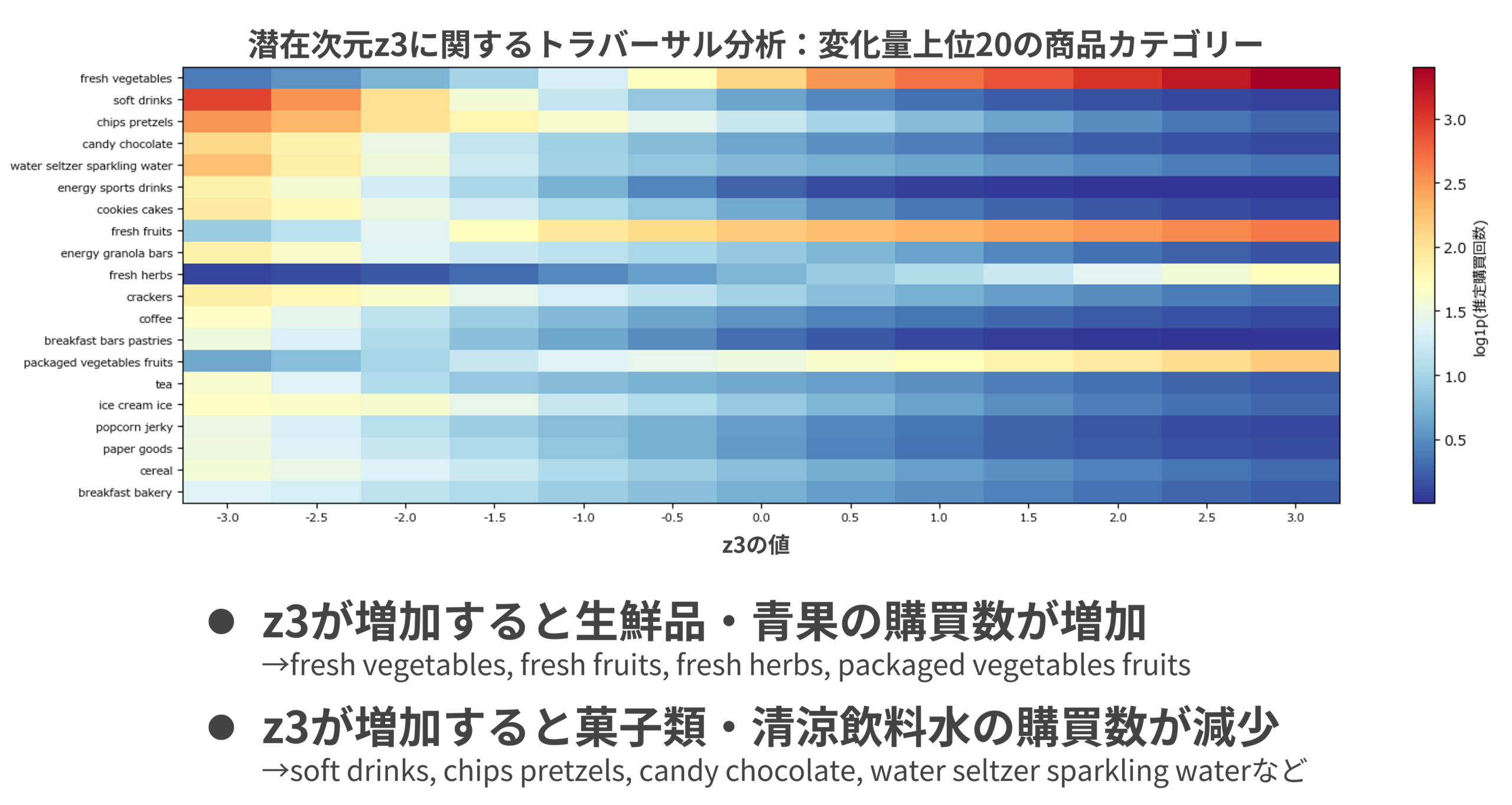
z3軸:健康志向
図7はz3軸に関するトラバーサル分析の結果だ。z3の値を増加させると、生鮮青果(fresh vegetables、fresh fruits、fresh herbs、packaged vegetables fruits)の購買数が顕著に増加する。対照的にいわゆるジャンクフード系カテゴリー(soft drink、chips pretzels、candy chocolate、energy sports drinks、cookies cakes)は大きく減少する。この軸は顧客の健康志向の強さを表現しており、値が低い側にはジャンクフード志向の顧客が位置する。
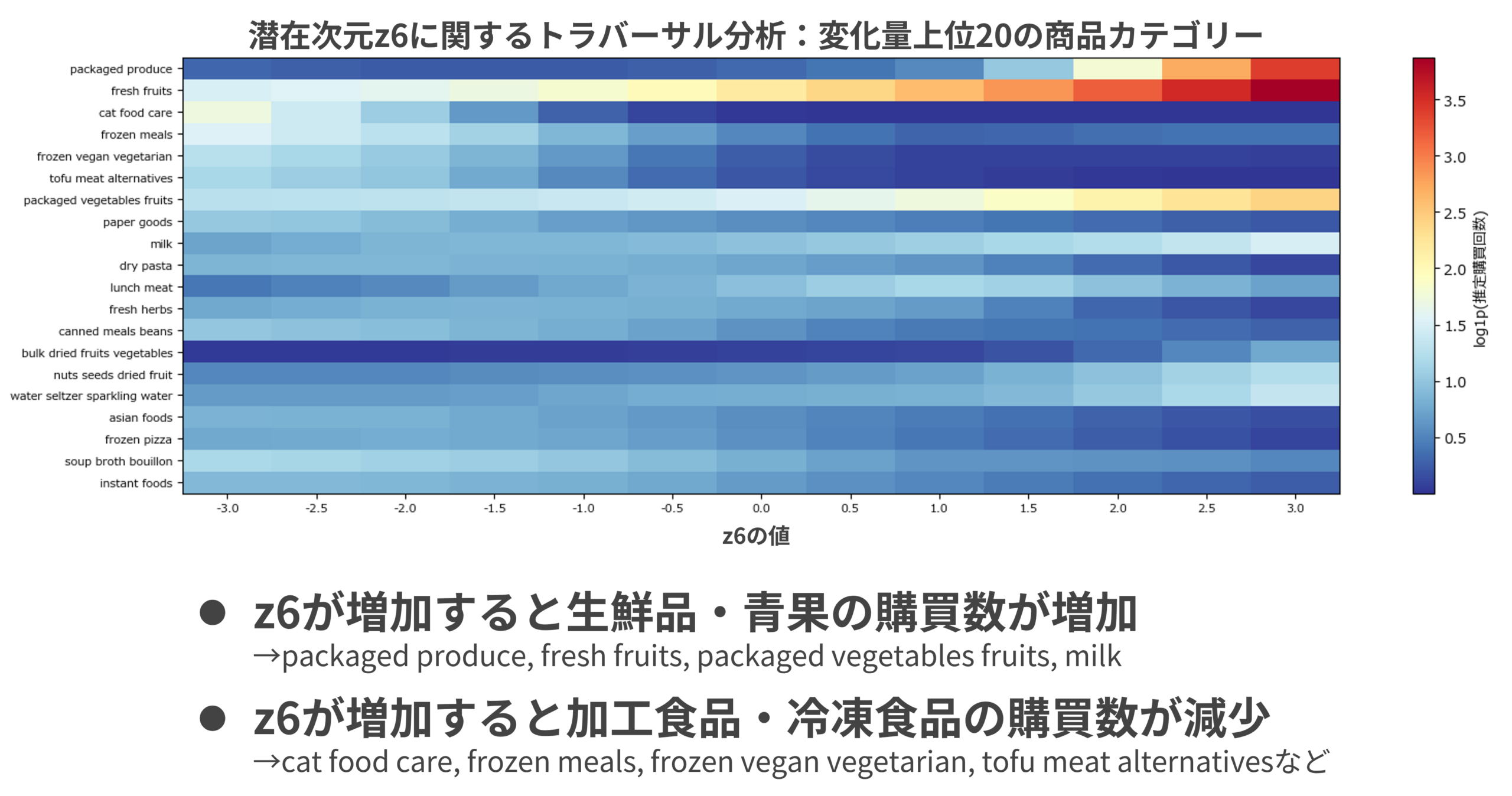
z6軸:ナチュラル志向+時短/少量買い
図8はz6軸に関するトラバーサル分析の結果だ。z6の値を増加させると、牛乳(milk)や即食系青果(fresh fruits、packaged produce、packaged vegetables fruits)のカテゴリーが増加する。z3との違いは、加工食品・冷凍食品(tofu meat alternatives、frozen meals、frozen vegan vegetarian)が顕著に減少する点だ。青果志向はz3と共通するが、z6はより非加工食品への志向が強く、かつpackagedから推測されるように時短または少量買いの傾向も備えていると解釈できる。健康志向の一段深い層としてz3とは独立した軸が形成された可能性があり非常に興味深い。
<ステップ3:顧客はどのように分布しているか?>
最後に、U-MAP(*4)というアルゴリズムを用いて各顧客の潜在変数を2次元プロット化し、z1・z3・z6それぞれの値の強弱をカラーリングで可視化した。図9中の点一つひとつはランダムサンプリングによって抽出された10,000人の顧客を表す。
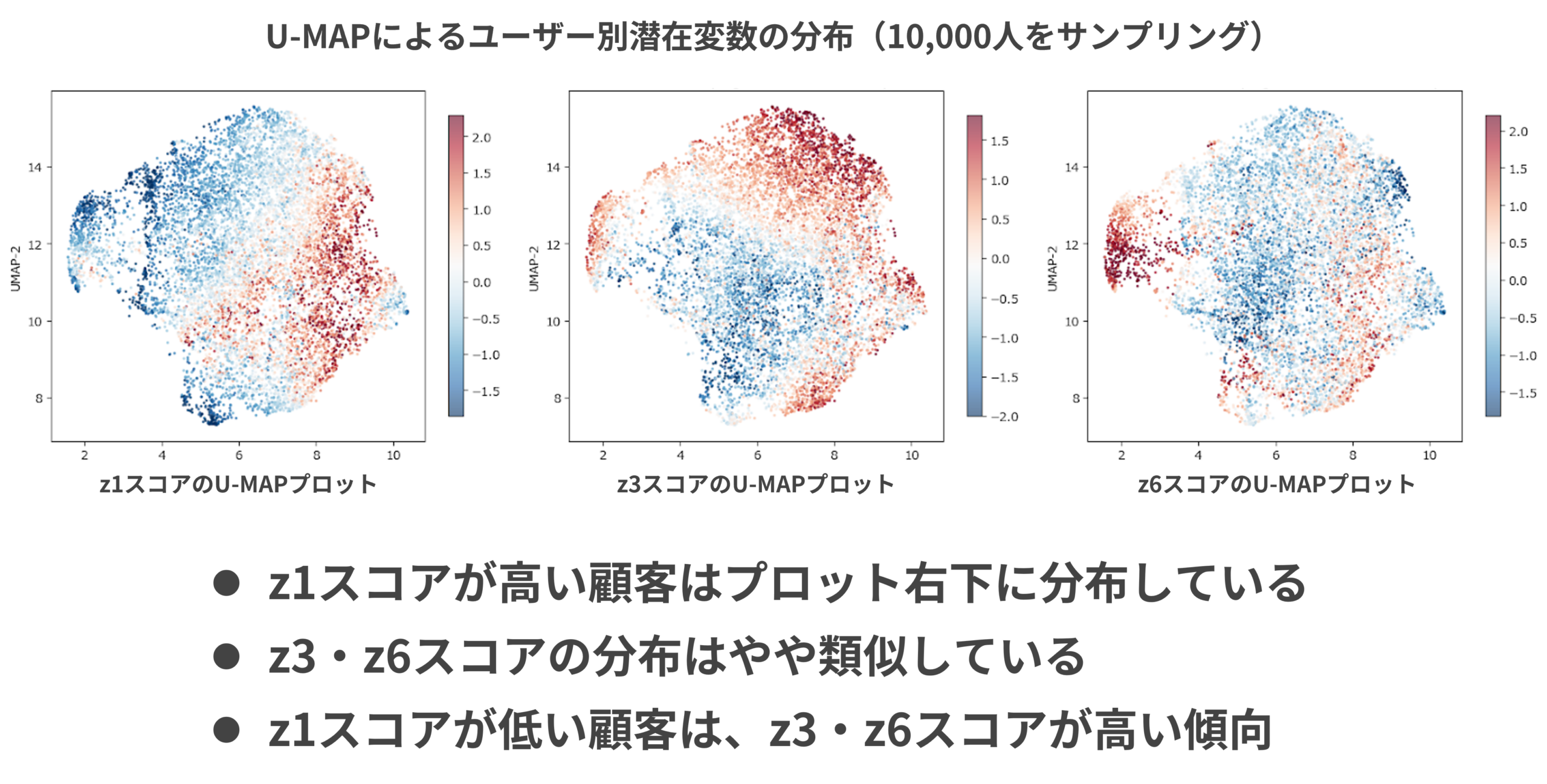
まず注目すべきはz3とz6のカラーリングの関係だ。z6(ナチュラル志向)が強い顧客群は、z3(健康志向)が強い領域の中に包含されるように分布している。これはナチュラル志向の顧客が健康志向の顧客の部分集合として存在していることを示しており、解釈としても極めて自然だ。健康を意識する顧客の中でも、特にその傾向が強い層がナチュラル志向へと分化している構造が、データから自律的に発見されたことになる。
もう1点、z1(購買アクティブ度)のカラーリングを重ねて観察すると、健康志向・ナチュラル志向が強い顧客ほど購買アクティブ度が低い傾向が見て取れる。これは直感に反するようにも思えるが、「必要なものだけを厳選して購入する」という行動様式の表れとして解釈することもできる。あるいは健康志向の強い顧客が、Instacartというデリバリーサービスよりも実店舗での購買を好む傾向があることを示唆している可能性もある。
(*4)U-MAPとは、高次元データにおけるデータ同士の局所的な関係性(近さ)を保ちながら、低次元空間に配置し直すことで構造を可視化する次元削減手法である。
おわりに:データは顧客の素顔を知っている
今回の分析で使用した情報は「誰が・どのカテゴリーの商品を・何個買ったか」というカウントデータのみだ。年齢も性別も住所も、商品の価格も販促履歴も存在しない。それでもVAEは、購買行動の背景に潜む顧客の嗜好構造を自律的に発見した。購買アクティブ度、健康志向、ナチュラル志向+時短/少量買いという3つの軸は、解釈を伴うものの軸そのものを人間が意図的に作ったわけではない。膨大な購買行動の集積の中に構造として存在していたものを、モデルが自ら見つけ出したのだ。
今回の分析はあくまでオープンデータを用いた検証であり、使用できる情報は最小限に制約されている。実際の小売企業が保有するデータ種ははるかに多い。商品の価格・プロモーション情報、顧客の来店頻度・滞在時間、会員属性情報などが加われば、潜在変数が捉える顧客像はさらに精緻で豊かになるだろう。
【出典】
[1]kaggle(2022), “InstaCart Online Grocery Basket Analysis Dataset”, https://www.kaggle.com/datasets/yasserh/instacart-online-grocery-basket-analysis-dataset (参照2026年4月13日)
[2]note 澁谷直樹(2025), “詳細VAE 変分オートエンコーダー”, https://note.com/kikaben/n/nc5e1b32bffc0 (参照2026年4月13日)







